Switching from Perl to Python: Speed
The job listings in scientific computing these days seem to show a mild preference for applicants with backgrounds in Python over Perl. It has high-profile (or just highly visible?) packages like NumPy and Python's MPI bindings for scientific computing, and some molecular dynamics packages (e.g., LAMMPS) include analysis routines written in Python. Although I've invested a few years into Perl, I've decided to not pigeonhole myself and start picking up Python. After all, Perl is unintelligible after it's been written, and it's sometimes frustrating to deal with its odd quirks.
To this end, I reimplemented one of my most-used Perl analysis routines in Python. Here is my Perl version, written back in 2009:
And here is the Python version I cooked up today:
In the Python version, there are several ways to tear through a file and I tried all three. Method #1 is closest to the Perl functionality, where I can specify multiple input files on the command line and have all of them parsed sequentially. Method #2 is the method that the Python documentation seems to advocate the most. Method #3 loads the whole file contents into memory and works from there.
Unfortunately, in all three cases, Python seems to be slower than Perl. Average execution times for a typical input file are:
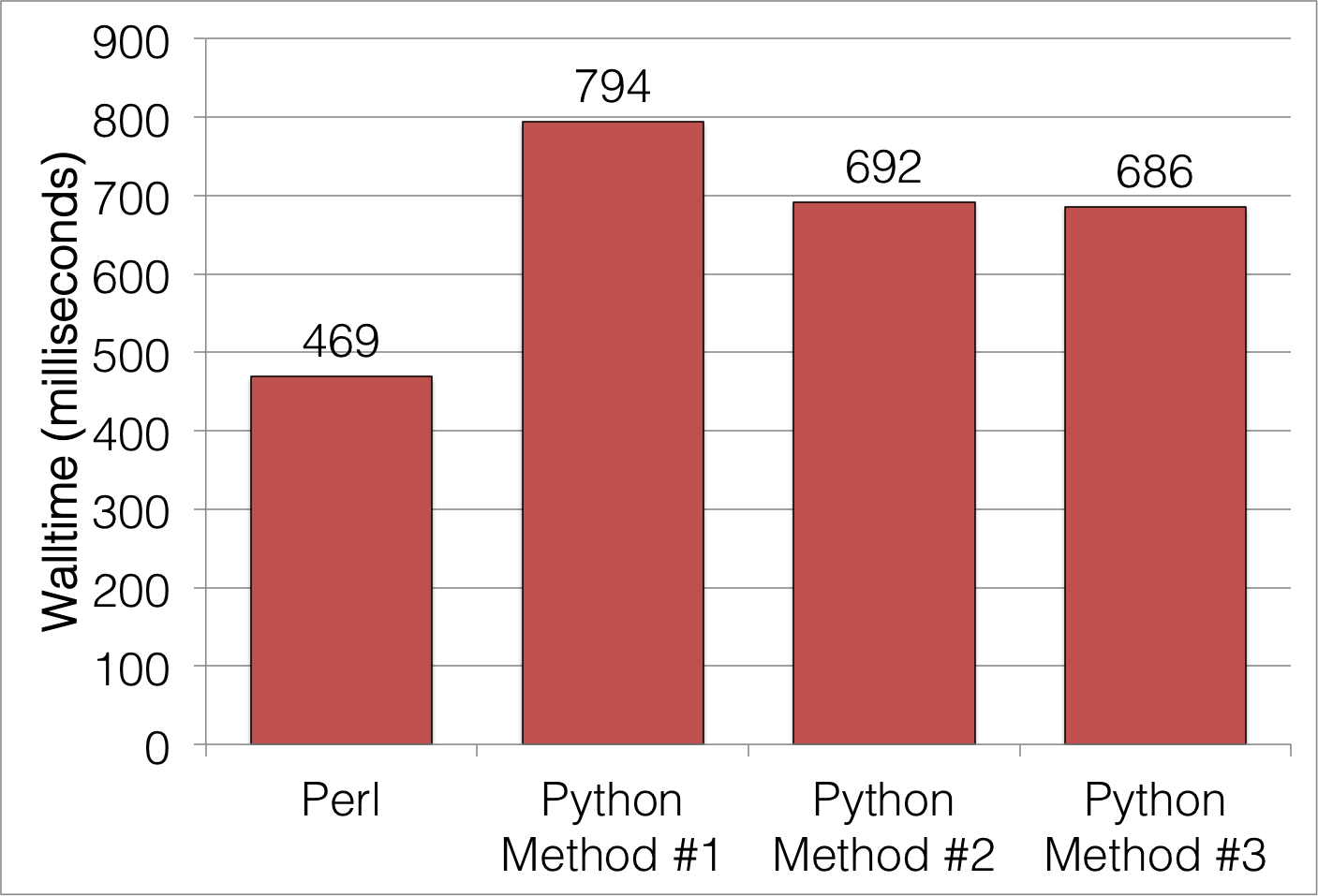
Maybe there's something I'm missing in the Python version, but the Perl version isn't exactly a shining example of simplicity in itself. What gives here? For a language that's being venerated in the scientific computing world, in the case of basic text parsing of large files, it isn't shining. At best, it's almost 50% slower than Perl.
To this end, I reimplemented one of my most-used Perl analysis routines in Python. Here is my Perl version, written back in 2009:
And here is the Python version I cooked up today:
In the Python version, there are several ways to tear through a file and I tried all three. Method #1 is closest to the Perl functionality, where I can specify multiple input files on the command line and have all of them parsed sequentially. Method #2 is the method that the Python documentation seems to advocate the most. Method #3 loads the whole file contents into memory and works from there.
Unfortunately, in all three cases, Python seems to be slower than Perl. Average execution times for a typical input file are:
Maybe there's something I'm missing in the Python version, but the Perl version isn't exactly a shining example of simplicity in itself. What gives here? For a language that's being venerated in the scientific computing world, in the case of basic text parsing of large files, it isn't shining. At best, it's almost 50% slower than Perl.