Skip to main content
Search
Search This Blog
Glenn K. Lockwood
Personal perspectives of a supercomputing enthusiast
HPC
Storage
Personal
About Me
My Website
More…
Posts
Showing posts from March, 2012
Show all
March 29, 2012
Netra T1 105
March 26, 2012
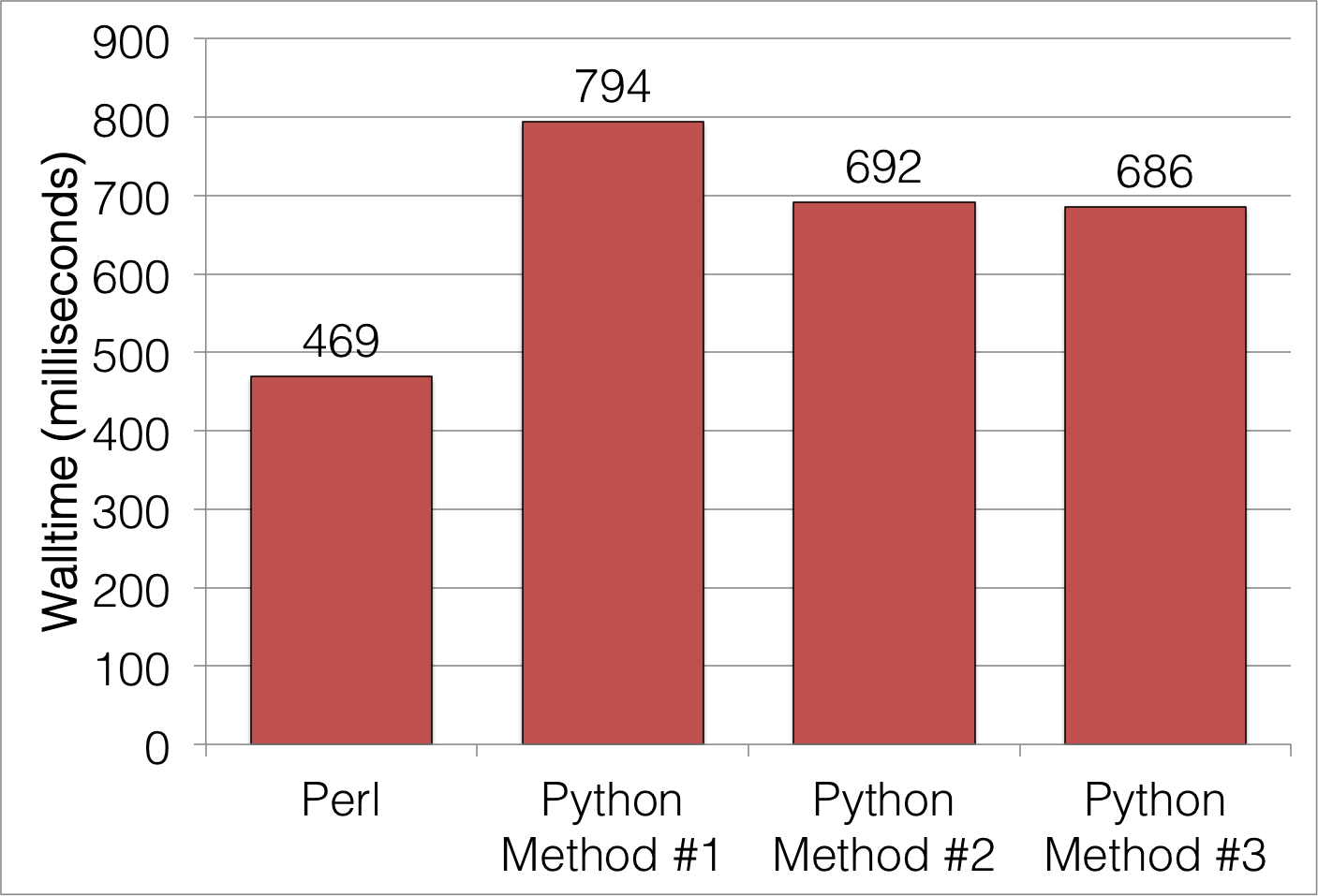
Switching from Perl to Python: Speed
Newer Posts
Home